Ah … real world problems require some proof-of-concept almost-finished implementation solutions.
This time I’m into figuring out what would be the best way to introduce full text search in one of my Delphi applications.
“Setup”
There’s a Delphi application operating on files. Files are located in various sub-folders and, with 99% certainty, files will not change – i.e. a provided folder and file structure is “ready only”. Folders and files are referred to using some XML as the backbone – just imagine an XML file where tags map to folders and subfolders (in a tree like fashion), files carry some attributes (name, title, version, owner, etc.) mapped to XML file-tag attributes.
The application, beside other stuff, offers search functionality for a user to locate / filter out those files “assigned to an owner” or “having a title” and alike – therefore something you could call a “metadata search”.
We are now looking into an option to provide something like full text search to the user – to have the ability to locate a file where the file content matches some token (word or partial word).
Due to the nature of the application and the nature of the target user audience, there are some requirements for any possible implementation: light implementation – must be easy to use, no complex third party engines, should work the same way on all Windows versions, no fat (paid) databases – therefore an implementation existing users will not be aware of. Also: preferably free (so the final price of the application for the end user does not go up) 🙂
For the sake of simplicity let’s say we are talking about TXT files. In reality the files are not TXT files – but whatever the file type actually is –we already know how to grab the textual content from it.
For the idea, here’s a simplified XML structure – all “file” tags should have all 3 attributes (name, title, owner):
<items root="E:\ftsTXTTest\A\">
<folder name="a1">
<file title="t" owner="o" name="n">a1\d14.txt</file>
<file title="t" owner="o" name="n">a1\d17.txt</file>
</folder>
<folder name="a2">
<file title="t" owner="o" name="n">a2\c6.txt</file>
<file title="t" owner="o" name="n">a2\c6per.txt</file>
<folder name="a21">
<file>a2\a21\announce.txt</file>
<file>a2\a21\announce_fr.txt</file>
</folder>
<folder name="a22">
<file>a2\a22\c6.txt</file>
<file>a2\a22\d6.txt</file>
<folder name"a221">
<file>a2\a22\a221\d11.txt</file>
<file>a2\a22\a221\d12.txt</file>
</folder>
</folder>
</items>
“Light” Full Text Search in Delphi
My initial idea was to check out what Windows as OS has to offer through its indexed Windows Search, but since each version of Windows brings something new I’ve very quickly decided not to go along that path.
I’ve spent some time investigating available options and it seemed it all boils down to either using some fat FTS engine/framework like Rubicon, Lucene, Sphinks OR rely on some database having built-in support for full text search.
Following the requirements stated before, I would want to go for a database having support for FTS queries. The database should be free, “natively” supported by Delphi and embedded (with no restrictions).
An embedded database is a database that does not run in a separate process, but instead is directly linked (embedded or integrated) into the application requiring access to the stored data. An embedded database is hidden from the application’s end-user and requires little or no ongoing maintenance.
Out of those embedded databases that include support for FTS queries – SQLite seems like the best choice.
SQLite is a software library that implements a self-contained, serverless, zero-configuration, transactional SQL database engine. SQLite is in the public domain and does not require a license.
Having picked SQLite the natural selection for me is FireDac (formerly AnyDac from Da-Soft).
FireDAC enables native high-speed direct access from Delphi to InterBase, SQLite, MySQL, SQL Server, Oracle, PostgreSQL, DB2, SQL Anywhere, Advantage DB, Firebird, Access, Informix, DataSnap and more.
To sum up the above:
- Task: provide full text search queries for a read-only folder-file structure (where file types are known and content can be programmatically extracted)
- At one time, in most cases, only 1 user will “attack” the folder (and the FTS database)
- Text extraction requires time – should be done out of users eyes
- Once extraction is done and content is stored, provide FTS type queries
- Requisites: light implementation, free, no fat-bulky engines, easy to setup and use from inside the existing application.
- Possible solution: SQLite + FireDac (+Delphi)
- Possible “problems”: speed of initial extraction, size of the database, updates to the database (even if read-only things happen), …
Complex and Less Complex Tasks In Implementing FTS
The “complex” part is the text extraction as it can take some time to extract the content (text) from files and store it in the database for FTS retrieval.
Once a folder is processed, and since we are talking about read-only locations, the search functionality from within the application is not a complex task. Text extraction could run in threads, be implemented as a Windows service or something alike – that’s something I still have to decide (read: try out).
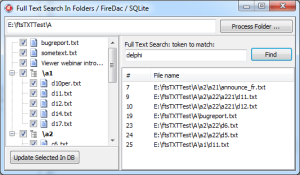
I’ve already done a proof of concept application using FireDac and SQLite and things seem to be nicely aligning to what the final goal is – of course on a small folder structure where text extraction takes a few seconds.
Next time I’ll share some code to how to create the FTS-enabled SQLite database supporting referential integrity and how to use FireDac.
As always is the case, I would not like to spend a few moths figuring out everything leads to a dead-end. 🙂
Any thoughts that you want to share, if you had some similar task to implement in your Delphi applications?
I would like to be as-sure-as-possible I’ve picked the right path.
Part 2: SQLite: Referential Integrity With Full Text Search Virtual Tables
Part 3: Full Text TXT Search In Delphi (+FireDac +SQLite). Sample Working Project.
SQLite interface is light and simple enough to not require any particular access components, you can use the SQLite API directly in such a scenario, and come out with simpler, shorter code and higher performance.
Use FTS4, WAL mode, NORMAL synchronization and it will fly.
If it helps, about 10 years ago our datbase app had a word processing like function (it integrated tightly with the database fields for mail merging & report writing). We implemented a full text search on these documents by indexing the document as it was saved in a background thread. The index was stored in a separate table with each word in the doc having an offset number too so we could use “near to” style queries. We never got around to implementing the `near to` query but the full text search worked great. Sounds like you’ve picked the right path 🙂
Why not Apache Solr with REST interface ?
Artur,
Thanks for the idea. This seems a bit too heavy for what we need (need to install server).
Hi Žarko,
apart from being embedded, I strongly suggest you to give a try to MongoDB.
*everything* you asked as for the requirements is provided by MongoDB.
I have developed a very large in-house application with MongoDB and mongo-delphi-drivers.
if you are just curious about it please drop me an email, I’ve spent about an year working with Delphi and MongoDB. So, given the times I’ve enjoyed your Delphi tips I would be more than happy to help you 😉
—
fabio vitale
FTS3 and FTS4 are great features of SQLite3. For most simple use, it is not mandatory to re-invent the wheel.
But I do not see the benefit of using FireDac over SQLite3 here. Direct SQLite3 access is enough, and faster.
Sphynx for Firebird is a more complete solution, for sure, but it is also heavier.
You have also Lucene / Mutis / Rubicon ports around.
For FullTextSearch in pure Delphi, NexusDB has such FTS – see http://www.nexusdb.com/support/index.php?q=fulltext-implementation
AFAIR the main article in the Delphi litterature about this is from Julian Bucknal.
You have the exact parser you need in The Delphi Magazine Issue 78, February 2002: “Algorithms Alfresco: Ask A Thousand Times Julian Bucknall discusses word indexing and document searches: if you want to know how Google works its magic this is the page to turn to.”
Advantage Database had great FullTextSearch capabilities and perfect SQL-Language extension to support it (similar to oracle). It was easy to install and it was easy to define a FullTextSearch-Index and easy to use in SQL.
Please don’t tell me that you intent on simply saving full texts into database and then doing serch thought theese texts. This could be quite slow when you have lots of textual data saved. Imagine searching through one huge textual file.
What I would recomend is using word compression when saving text to database.
This would look something like this:
1. Create a database table which would contain all used words (dictionary).
2. Create anoter database table which would hold basic informations about files like Filenames, locations, files timestamp (File Record Table).
3. For every word saved in dictionary table you create yourself a new database table into which you will save information about current word ocurance in your files. (Word ocurance table) This is done by simply storing record indexes from File Records Table.
What this system would provide is ability to quickly see if the word you are serching has been even used (searching through dictionarry alone). You can always include partial searches which would return you several reacords. Same goes for multiple words.
You can then eazily find out in which files do theese words ocur by seaching though Word Ocurance Table for each desired word. When searching for multiple words you combine search results for each word.
So now you get the information in which files do your searched words ocur.
If you need the ability to find whole scentances than you can create another set of database tables for each file into which you will save word compressed text. You already have Word Dictionary so instead of saving plain text you will only be saving Word Indexes from Dictionary table.
Now since text can also contain some special characters and such you would probably like to reserve several initial indexes in Word Dictionary Table for theese.
The main reason why you should use word compression for this is that by doing so you will greatly reduce the size of your database. Why is that?
If you use Word (16 bits) for saving Word Indexes (upto 65,535 posible words in dictionary) it means that you can save space for every word with more than 2 characters in it especially if theese contain Unicode characters (AnisChar = 8 bits, Unicode Char or WIdeChar = 16 bits).
Now you can monitor file changes simply by registering OnFileChange system event or by checking file TimeSpamps (usefull for detecting file changes during the time your program wasn’t running).
Best thing about this system is that for this you can actually make your own custom database simply by using Typed files. This way you make this system platform independable.
And yes the way how this system works is much similar to the one Windows Search 4 uses for Indepth file search.
Thanks for the comments. If I’m not wrong what you propose to do is what databases supporting FTS queries and “match” or “nearby” searches already do internally: indexing “tokens”, etc.
I wouldn’t know about that as I’m focusing on game development and therefore have no need to use databases.
🙂
Hi Zarko & everybody else,
The FPC compiler source comes with code that allows you to build a full-text search solution in Object Pascal using e.g.. Firebird or SQLite, see e.g.
http://wiki.lazarus.freepascal.org/fpindexer
Perhaps it’s a bit late, but it might be useful for inspiration/copying (license is LGPL with linking exception).